搜索到
5
篇与
工作笔记
的结果
-
 XMind安装步骤 一:首先先把网盘的这个鬼东西下载到自己电脑上,下载位置随意,然后打开这个鬼东西某盘软件连接:https://www.aliyundrive.com/s/CfymQSGD6Hj1.安装Xmind-for-Windows-64bit-22.10.0631.exe,一直点同意和下一步,安装完成后关闭Xmind(一定要关闭这个鬼东西)2.重点来了!!!复制x64_Patch[阿然资源社]文件夹中的“winmm.dll”到安装目录,默认如下:C:Users你的用户名AppDataLocalProgramsXmind(不知道路径的看下方图片,一步步操作即可,软件我挂某盘连接里)3.然后打开Xmind,看右上角如果显示试用,就关闭了重新打开。如果还是显示试用,就再关闭了重新打开(意思就是需要重新打开软件两次)
XMind安装步骤 一:首先先把网盘的这个鬼东西下载到自己电脑上,下载位置随意,然后打开这个鬼东西某盘软件连接:https://www.aliyundrive.com/s/CfymQSGD6Hj1.安装Xmind-for-Windows-64bit-22.10.0631.exe,一直点同意和下一步,安装完成后关闭Xmind(一定要关闭这个鬼东西)2.重点来了!!!复制x64_Patch[阿然资源社]文件夹中的“winmm.dll”到安装目录,默认如下:C:Users你的用户名AppDataLocalProgramsXmind(不知道路径的看下方图片,一步步操作即可,软件我挂某盘连接里)3.然后打开Xmind,看右上角如果显示试用,就关闭了重新打开。如果还是显示试用,就再关闭了重新打开(意思就是需要重新打开软件两次) -
SpringBoot日志基本查看 1. 日志的作用日志是程序的重要组成部分,在程序报错的时候,如果我们不看日志,是很难排查出错误的,除非你真的是很有经验.所以日志最主要的作用就是排除和定位问题.日志提供的功能:记录⽤户登录⽇志,⽅便分析⽤户是正常登录还是恶意⽤户。记录系统的操作⽇志,⽅便数据恢复和定位操作⼈。记录程序的执⾏时间,⽅便为以后优化程序提供数据⽀持2.使用日志对象提供的方法打印日志import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.stereotype.Controller; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.ResponseBody; @Controller @ResponseBody public class UserController { //1. 先得到日志对象(来自 slf4j) private static final Logger log = LoggerFactory.getLogger(UserController.class); //设置当前的类型 @RequestMapping("/sayhi") public void sayHi(){ //2. 使用日志对象提供的打印方法进行日志打印 log.trace("我是 trace"); log.debug("我是 debug"); log.info("我是 info"); log.warn("我是 warn"); log.error("我是 error"); } }有些没打印,因为他只会打印跟他同级别的或者比他级别高的日志,他这里默认是 info 级别.3.日志级别分类日志级别分为:trace: 微量,少许的意思(级别最低)debug: 调试日志info: 普通信息日志warn: 警告日志error: 错误日志fatal: 致命的日志(系统输出的日志,不能自定义打印)日志级别的顺序:越往上接收到的消息就越少。注意:fatal 是不支持打印的,因为你程序都崩溃了,你还打印个锤子。。。而且, 日志对象 也没有提供 关于 fatal 的 方法、全局日志级别
-
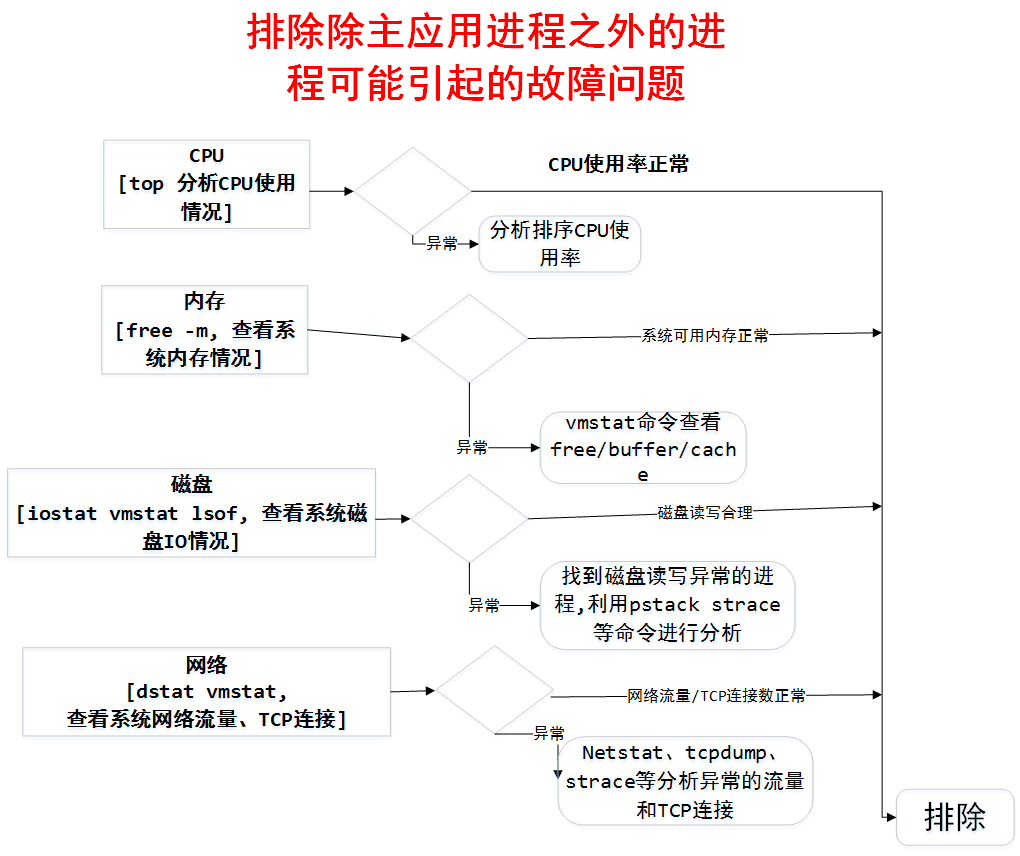
Java 服务线上问题排查思路与工具使用 Java 服务常见线上问题所有 Java 服务的线上问题从系统表象来看归结起来总共有四方面:CPU、内存、磁盘、网络。例如 CPU 使用率峰值突然飚高、内存溢出(泄露)、磁盘满了、网络流量异常、FullGC 等等问题。基于这些现象我们可以将线上问题分成两大类: 系统异常、业务服务异常。系统异常常见的系统异常现象包括: CPU 占用率过高、CPU上下文切换频率次数较高、磁盘满了、磁盘 I/O 过于频繁、网络流量异常(连接数过多)、系统可用内存长期处于较低值(导致 oom killer)等等。这些问题可以通过 top(cpu)、free(内存)、df(磁盘)、dstat(网络流量)、pstack、vmstat、strace(底层系统调用)等工具获取系统异常现象数据。此外,如果对系统以及应用进行排查后,均未发现异常现象的根本原因,那么也有可能是因为外部基础设施 IAAS 平台所引发的问题。例如运营商网络或者云服务提供商偶尔可能也会发生一些故障问题,你的引用只有某个区域如广东用户访问系统时发生服务不可用现象,那么极有可能是这些原因导致的。今天,我司部署在阿里云华东地域的业务系统中午时分突然不能为广东地区用户提供正常服务,对系统进行各种排查均为发现任何问题。最后,通过查询阿里云公告得知原因是"广东地区电信线路访问华东地区互联网资源(包含阿里云华东1地域)出现网络丢包或者延迟增大的异常情况"。业务服务异常常见的业务服务异常现象包括: PV 量过高、服务调用耗时异常、线程死锁、多线程并发问题、频繁进行 Full GC、异常安全攻击扫描等。问题定位我们一般会采用排除法,从外部排查到内部排查的方式来定位线上服务问题。首先我们要排除其他进程(除主进程之外)可能引起的故障问题 其次排除业务应用可能引起的故障问题 最后可以考虑是否为运营商或者云服务提供商所引起的故障定位流程系统异常排查流程业务应用排查流程Linux 常用的性能分析工具Linux 常用的性能分析工具使用包括 : top(cpu)、free(内存)、df(磁盘)、dstat(网络流量)、pstack、vmstat、strace(底层系统调用)等。CPUCPU 是系统重要的监控指标,能够分析系统的整体运行状况。监控指标一般包括运行队列、CPU使用率和上下文切换等。top命令是Linux下常用的 CPU 性能分析工具,能够实时显示系统中各个进程的资源占用状况,常用于服务端性能分析。 top 命令显示了各个进程 CPU 使用情况,一般 CPU 使用率从高到低排序展示输出。其中 Load Average 显示最近1分钟、5分钟和15分钟的系统平均负载,上图各值为2.46,1.96,1.99。 我们一般会关注 CPU 使用率最高的进程,正常情况下就是我们的应用主进程。第七行以下:各进程的状态监控。PID : 进程id USER : 进程所有者 PR : 进程优先级 NI : nice值。负值表示高优先级,正值表示低优先级 VIRT : 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES RES : 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA SHR : 共享内存大小,单位kb S : 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程 %CPU : 上次更新到现在的CPU时间占用百分比 %MEM : 进程使用的物理内存百分比 TIME+ : 进程使用的CPU时间总计,单位1/100秒 COMMAND : 进程名称内存内存是排查线上问题的重要参考依据,内存问题很多时候是引起 CPU 使用率较高的见解因素。系统内存:free 是显示的当前内存的使用,-m 的意思是M字节来显示内容。部分参数说明: total 内存总数: 3790Mused 已经使用的内存数: 1880Mfree 空闲的内存数: 118Mshared 当前已经废弃不用,总是0buffers Buffer 缓存内存数: 1792M磁盘磁盘满了很多时候会连带引起系统服务不可用等问题df -hdu -m /path网络dstat 命令可以集成了 vmstat、iostat、netstat 等等工具能完成的任务。dstat -c cpu情况 -d 磁盘读写 -n 网络状况 -l 显示系统负载 -m 显示形同内存状况 -p 显示系统进程信息 -r 显示系统IO情况其它vmstatvmstat 2 10 -tvmstat 是 Virtual Meomory Statistics(虚拟内存统计)的缩写, 是实时系统监控工具。该命令通过使用 knlist 子程序和 /dev/kmen 伪设备驱动器访问这些数据,输出信息直接打印在屏幕。使用 vmstat 2 10 -t命令,查看 io 的情况 (第一个参数是采样的时间间隔数单位是秒,第二个参数是采样的次数)。JVM 定位问题工具在 JDK 安装目录的 bin 目录下默认提供了很多有价值的命令行工具。每个小工具体积基本都比较小,因为这些工具只是 jdklibtools.jar 的简单封装。其中,定位排查问题时最为常用命令包括:jps(进程)、jmap(内存)、jstack(线程)、jinfo(参数)等。jps:查询当前机器所有JAVA进程信息jmap:输出某个 Java 进程内存情况(如产生那些对象及数量等)jstack:打印某个 Java 线程的线程栈信息jinfo:用于查看 jvm 的配置参数jps 命令jps 用于输出当前用户启动的所有进程 ID,当线上发现故障或者问题时,能够利用 jps 快速定位对应的 Java 进程 ID。jps -l -m -m -l -l参数用于输出主启动类的完整路径当然,我们也可以使用 Linux 提供的查询进程状态命令,例如:ps -ef | grep tomcat我们也能快速获取 Tomcat 服务的进程 id。jmap 命令jmap -heap pid 输出当前进程JVM堆新生代、老年代、持久代等请情况,GC使用的算法等信息 jmap -histo:live {pid} | head -n 10 输出当前进程内存中所有对象包含的大小 jmap -dump:format=b,file=/usr/local/logs/gc/dump.hprof {pid} 以二进制输出档当前内存的堆情况,然后可以导入MAT等工具进行JMap(Java Memory Map)可以输出所有内存中对象的工具,甚至可以将 VM 中的 heap,以二进制输出成文本。jmap -heap pid:jmap -heap pid 输出当前进程JVM堆新生代、老年代、持久代等请情况,GC使用的算法等信息jmap 可以查看 JVM 进程的内存分配与使用情况,使用 的 GC 算法等信息。jmap -histo:live {pid} | head -n 10:jmap -histo:live {pid} | head -n 10 输出当前进程内存中所有对象包含的大小输出当前进程内存中所有对象实例数(instances)和大小(bytes),如果某个业务对象实例数和大小存在异常情况,可能存在内存泄露或者业务设计方面存在不合理之处。jmap -dump:jmap -dump:format=b,file=/usr/local/logs/gc/dump.hprof {pid} -dump:formate=b,file= 以二进制输出当前内存的堆情况至相应的文件,然后可以结合 MAT 等内存分析工具深入分析当前内存情况。一般我们要求给 JVM 添加参数 -XX:+Heap Dump On Out Of Memory Error OOM 确保应用发生 OOM 时 JVM 能够保存并 dump 出当前的内存镜像。当然如果你决定手动 dump 内存时,dump 操作占据一定 CPU 时间片、内存资源、磁盘资源等,因此会带来一定的负面影响。此外,dump 的文件可能比较大,一般我们可以考虑使用zip命令对文件进行压缩处理,这样在下载文件时能减少带宽的开销。在下载 dump 文件完成之后,由于 dump 文件较大可将 dump 文件备份至制定位置或者直接删除,以释放磁盘在这块的空间占用。jstack 命令printf '%x\n' tid --> 10进制至16进制线程ID(navtive线程) %d 10进制 jstack pid | grep tid -C 30 --color ps -mp 8278 -o THREAD,tid,time | head -n 40某 Java 进程 CPU 占用率高,我们想要定位到其中 CPU 占用率最高的线程。(1) 利用 top 命令可以查出占 CPU 最高的线程 pidtop -Hp {pid}(2) 占用率最高的线程 ID 为 6900,将其转换为16进制形式(因为 java native 线程以16进制形式输出)printf '%x\n' 6900(3) 利用 jstack 打印出 Java 线程调用栈信息jstack 6418 | grep '0x1af4' -A 50 --color内存分析工具 MAT什么是 MAT?MAT(Memory Analyzer Tool),一个基于 Eclipse 的内存分析工具,是一个快速、功能丰富的 JAVA heap 分析工具,它可以帮助我们查找内存泄漏和减少内存消耗。使用内存分析工具从众多的对象中进行分析,快速的计算出在内存中对象的占用大小,看看是谁阻止了垃圾收集器的回收工作,并可以通过报表直观的查看到可能造成这种结果的对象。右侧的饼图显示当前快照中最大的对象。单击工具栏上的柱状图,可以查看当前堆的类信息,包括类的对象数量、浅堆(Shallow heap)、深堆(Retained Heap)。浅堆表示一个对象结构所占用内存的大小。深堆表示一个对象被回收后,可以真实释放的内存大小。支配树(The Dominator Tree): 列出了堆中最大的对象,第二层级的节点表示当被第一层级的节点所引用到的对象,当第一层级对象被回收时,这些对象也将被回收。这个工具可以帮助我们定位对象间的引用情况,垃圾回收时候的引用依赖关系 Path to GC Roots 被JVM持有的对象,如当前运行的线程对象,被systemclass loader加载的对象被称为GC Roots, 从一个对象到GC Roots的引用链被称为Path to GC Roots, 通过分析Path to GC Roots可以找出JAVA的内存泄露问题,当程序不在访问该对象时仍存在到该对象的引用路径。 日志分析GC 日志分析GC 日志详细分析Java 虚拟机 GC 日志是用于定位问题重要的日志信息,频繁的 GC 将导致应用吞吐量下降、响应时间增加,甚至导致服务不可用-XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:/usr/local/gc/gc.log -XX:+UseConcMarkSweepGC我们可以在 Java 应用的启动参数中增加 -XX:+PrintGCDetails 可以输出 GC 的详细日志,例外还可以增加其他的辅助参数,如 -Xloggc 制定 GC 日志文件地址。如果你的应用还没有开启该参数,下次重启时请加入该参数。上图为线上某应用在平稳运行状态下的GC日志截图。2017-12-29T18:25:22.753+0800: 73143.256: [GC2017-12-29T18:25:22.753+0800: 73143.257: [ParNew: 559782K->1000K(629120K), 0.0135760 secs] 825452K->266673K(2027264K), 0.0140300 secs] [Times: user=0.02 sys=0.00, real=0.02 secs] 解析说明: [2017-12-29T18:25:22.753+0800: 73143.256] : 自JVM启动73143.256秒时发生本次GC. [ParNew: 559782K->1000K(629120K), 0.0135760 secs] : 对新生代进行的GC,使用ParNew收集器,559782K是新生代回收前的大小,1000K是新生代回收后大小,629120K是当前新生代分配的内存总大小, 0.0135760 secs表示本次新生代回收耗时 0.0135760秒 [825452K->266673K(2027264K), 0.0140300 secs]:825452K是回收堆内存大小,266673K是回收堆之后内存大小,2027264K是当前堆内存总大小,0.0140300 secs表示本次回收共耗时0.0140300秒 [Times: user=0.02 sys=0.00, real=0.02 secs] : 用户态耗时0.02秒,系统态耗时0.00,实际耗时0.02秒无论是 minor GC 或者是 Full GC,我们主要关注 GC 回收实时耗时, 如 real=0.02secs,即 stop the world 时间,如果该时间过长,则严重影响应用性能。CMS GC 日志分析Concurrent Mark Sweep(CMS)是老年代垃圾收集器,从名字(Mark Sweep)可以看出,CMS 收集器就是“标记-清除”算法实现的,分为六个步骤:初始标记(STW initial mark)并发标记(Concurrent marking)并发预清理(Concurrent precleaning)重新标记(STW remark)并发清理(Concurrent sweeping)并发重置(Concurrent reset)其中初始标记(STW initial mark) 和 重新标记(STW remark)需要“Stop the World”。初始标记 :在这个阶段,需要虚拟机停顿正在执行的任务,官方的叫法 STW(Stop The Word)。这个过程从垃圾回收的"根对象"开始,只扫描到能够和"根对象"直接关联的对象,并作标记。所以这个过程虽然暂停了整个 JVM,但是很快就完成了。并发标记 :这个阶段紧随初始标记阶段,在初始标记的基础上继续向下追溯标记。并发标记阶段,应用程序的线程和并发标记的线程并发执行,所以用户不会感受到停顿。并发预清理 :并发预清理阶段仍然是并发的。在这个阶段,虚拟机查找在执行并发标记阶段新进入老年代的对象(可能会有一些对象从新生代晋升到老年代, 或者有一些对象被分配到老年代)。通过重新扫描,减少下一个阶段"重新标记"的工作,因为下一个阶段会 Stop The World。重新标记 :这个阶段会暂停虚拟机,收集器线程扫描在 CMS 堆中剩余的对象。扫描从"跟对象"开始向下追溯,并处理对象关联。并发清理 :清理垃圾对象,这个阶段收集器线程和应用程序线程并发执行。并发重置 :这个阶段,重置 CMS 收集器的数据结构,等待下一次垃圾回收。CMS 使得在整个收集的过程中只是很短的暂停应用的执行,可通过在 JVM 参数中设置 -XX:UseConcMarkSweepGC 来使用此收集器,不过此收集器仅用于 old 和 Perm(永生)的对象收集。CMS 减少了 stop the world 的次数,不可避免地让整体 GC 的时间拉长了。Full GC 的次数说的是 stop the world 的次数,所以一次 CMS 至少会让 Full GC 的次数+2,因为 CMS Initial mark 和 remark 都会 stop the world,记做2次。而 CMS 可能失败再引发一次 Full GC。上图为线上某应用在进行 CMS GC 状态下的 GC 日志截图。2017-11-02T09:27:03.989+0800: 558115.552: [GC [1 CMS-initial-mark: 1774783K(1926784K)] 1799438K(2068800K), 0.0123430 secs] [Times: user=0.01 sys=0.01, real=0.02 secs] 2017-11-02T09:27:04.001+0800: 558115.565: [CMS-concurrent-mark-start] 2017-11-02T09:27:04.714+0800: 558116.277: [CMS-concurrent-mark: 0.713/0.713 secs] [Times: user=1.02 sys=0.03, real=0.71 secs] 2017-11-02T09:27:04.714+0800: 558116.277: [CMS-concurrent-preclean-start] 2017-11-02T09:27:04.722+0800: 558116.285: [CMS-concurrent-preclean: 0.008/0.008 secs] [Times: user=0.01 sys=0.00, real=0.01 secs] 2017-11-02T09:27:04.722+0800: 558116.286: [CMS-concurrent-abortable-preclean-start] 2017-11-02T09:27:04.836+0800: 558116.399: [GC2017-11-02T09:27:04.836+0800: 558116.400: [ParNew: 138301K->6543K(142016K), 0.0155540 secs] 1913085K->1781327K(2068800K), 0.0160610 secs] [Times: user=0.03 sys=0.01, real=0.02 secs] 2017-11-02T09:27:05.005+0800: 558116.569: [CMS-concurrent-abortable-preclean: 0.164/0.283 secs] [Times: user=0.46 sys=0.02, real=0.28 secs] 2017-11-02T09:27:05.006+0800: 558116.570: [GC[YG occupancy: 72266 K (142016 K)]2017-11-02T09:27:05.006+0800: 558116.570: [Rescan (parallel) , 0.2523940 secs]2017-11-02T09:27:05.259+0800: 558116.822: [weak refs processing, 0.0011240 secs]2017-11-02T09:27:05.260+0800: 558116.823: [scrub string table, 0.0028570 secs] [1 CMS-remark: 1774783K(1926784K)] 1847049K(2068800K), 0.2566410 secs] [Times: user=0.14 sys=0.00, real=0.26 secs] 2017-11-02T09:27:05.265+0800: 558116.829: [CMS-concurrent-sweep-start] 2017-11-02T09:27:05.422+0800: 558116.986: [GC2017-11-02T09:27:05.423+0800: 558116.986: [ParNew: 120207K->2740K(142016K), 0.0179330 secs] 1885446K->1767979K(2068800K), 0.0183340 secs] [Times: user=0.03 sys=0.01, real=0.02 secs] 2017-11-02T09:27:06.240+0800: 558117.804: [GC2017-11-02T09:27:06.240+0800: 558117.804: [ParNew: 116404K->3657K(142016K), 0.0134680 secs] 1286444K->1173697K(2068800K), 0.0138460 secs] [Times: user=0.03 sys=0.00, real=0.01 secs] 2017-11-02T09:27:06.966+0800: 558118.530: [GC2017-11-02T09:27:06.966+0800: 558118.530: [ParNew: 117321K->2242K(142016K), 0.0135210 secs] 738838K->623759K(2068800K), 0.0140130 secs] [Times: user=0.03 sys=0.00, real=0.02 secs] 2017-11-02T09:27:07.144+0800: 558118.708: [CMS-concurrent-sweep: 1.820/1.879 secs] [Times: user=2.88 sys=0.14, real=1.88 secs] 2017-11-02T09:27:07.144+0800: 558118.708: [CMS-concurrent-reset-start] 2017-11-02T09:27:07.149+0800: 558118.713: [CMS-concurrent-reset: 0.005/0.005 secs] [Times: user=0.01 sys=0.00, real=0.00 secs] 如果你已掌握 CMS 的垃圾收集过程,那么上面的 GC 日志你应该很容易就能看的懂,这里我就不详细展开解释说明了。此外 CMS 进行垃圾回收时也有可能会发生失败的情况。异常情况有:伴随 prommotion failed,然后 Full GC:[prommotion failed:存活区内存不足,对象进入老年代,而此时老年代也仍然没有内存容纳对象,将导致一次Full GC]伴随 concurrent mode failed,然后 Full GC:[concurrent mode failed:CMS回收速度慢,CMS完成前,老年代已被占满,将导致一次Full GC]频繁 CMS GC:[内存吃紧,老年代长时间处于较满的状态]
-
使用top命令分析java程序占用内存 ps aux命令执行结果的几个列的信息的含义USER 进程所属用户 PID 进程ID %CPU 进程占用CPU百分比 %MEM 进程占用内存百分比 VSZ 虚拟内存占用大小 单位:kb(killobytes) RSS 实际内存占用大小 单位:kb(killobytes) TTY 终端类型 STAT 进程状态 START 进程启动时刻 TIME 进程运行时长,进程已经消耗的CPU时间 COMMAND 启动进程的命令的名称和参数top 命令 VSZ,RSS,TTY,STAT, VIRT,RES,SHR,DATA的含义VIRT:virtual memory usage 虚拟内存 1、进程“需要的”虚拟内存大小,包括进程使用的库、代码、数据等 2、假如进程申请100m的内存,但实际只使用了10m,那么它会增长100m,而不是实际的使用量 RES:resident memory usage 常驻内存 1、进程当前使用的内存大小,但不包括swap out 2、包含其他进程的共享 3、如果申请100m的内存,实际使用10m,它只增长10m,与VIRT相反 4、关于库占用内存的情况,它只统计加载的库文件所占内存大小 SHR:shared memory 共享内存 1、除了自身进程的共享内存,也包括其他进程的共享内存 2、虽然进程只使用了几个共享库的函数,但它包含了整个共享库的大小 3、计算某个进程所占的物理内存大小公式:RES – SHR 4、swap out后,它将会降下来 DATA 1、数据占用的内存。如果top没有显示,按f键可以显示出来。 2、真正的该程序要求的数据空间,是真正在运行中要使用的。 top 运行中可以通过 top 的内部命令对进程的显示方式进行控制。内部命令如下: s – 改变画面更新频率 l – 关闭或开启第一部分第一行 top 信息的表示 t – 关闭或开启第一部分第二行 Tasks 和第三行 Cpus 信息的表示 m – 关闭或开启第一部分第四行 Mem 和 第五行 Swap 信息的表示 N – 以 PID 的大小的顺序排列表示进程列表 P – 以 CPU 占用率大小的顺序排列进程列表 M – 以内存占用率大小的顺序排列进程列表 h – 显示帮助 n – 设置在进程列表所显示进程的数量 q – 退出 top s – 改变画面更新周期 序号 列名 含义 a PID 进程id b PPID 父进程id c RUSER Real user name d UID 进程所有者的用户id e USER 进程所有者的用户名 f GROUP 进程所有者的组名 g TTY 启动进程的终端名。不是从终端启动的进程则显示为 ? h PR 优先级 i NI nice值。负值表示高优先级,正值表示低优先级 j P 最后使用的CPU,仅在多CPU环境下有意义 k %CPU 上次更新到现在的CPU时间占用百分比 l TIME 进程使用的CPU时间总计,单位秒 m TIME+ 进程使用的CPU时间总计,单位1/100秒 n %MEM 进程使用的物理内存百分比 o VIRT 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES p SWAP 进程使用的虚拟内存中,被换出的大小,单位kb。 q RES 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA r CODE 可执行代码占用的物理内存大小,单位kb s DATA 可执行代码以外的部分(数据段+栈)占用的物理内存大小,单位kb t SHR 共享内存大小,单位kb u nFLT 页面错误次数 v nDRT 最后一次写入到现在,被修改过的页面数。 w S 进程状态。(D=不可中断的睡眠状态,R=运行,S=睡眠,T=跟踪/停止,Z=僵尸进程) x COMMAND 命令名/命令行 y WCHAN 若该进程在睡眠,则显示睡眠中的系统函数名 z Flags 任务标志,参考 sched.h 默认情况下仅显示比较重要的 PID、USER、PR、NI、VIRT、RES、SHR、S、%CPU、%MEM、TIME+、COMMAND 列。可以通过下面的快捷键来更改显示内容。 通过 f 键可以选择显示的内容。按 f 键之后会显示列的列表,按 a-z 即可显示或隐藏对应的列,最后按回车键确定。 按 o 键可以改变列的显示顺序。按小写的 a-z 可以将相应的列向右移动,而大写的 A-Z 可以将相应的列向左移动。最后按回车键确定。 按大写的 F 或 O 键,然后按 a-z 可以将进程按照相应的列进行排序。而大写的 R 键可以将当前的排序倒转。jmap命令jmap -heap 进程ID Attaching to process ID 17775, please wait... Debugger attached successfully. Server compiler detected. JVM version is 25.121-b13 using thread-local object allocation. Parallel GC with 2 thread(s) parallel并发垃圾回收器 Heap Configuration: MinHeapFreeRatio = 0 MaxHeapFreeRatio = 100 MaxHeapSize = 1006632960 (960.0MB) 当前JVM最大堆大小 NewSize = 20971520 (20.0MB) MaxNewSize = 335544320 (320.0MB) OldSize = 41943040 (40.0MB) NewRatio = 2 SurvivorRatio = 8 MetaspaceSize = 21807104 (20.796875MB) 当前元空间大小 CompressedClassSpaceSize = 1073741824 (1024.0MB) MaxMetaspaceSize = 17592186044415 MB 元空间最大大小 G1HeapRegionSize = 0 (0.0MB) Heap Usage: PS Young Generation Eden Space: capacity = 25165824 (24.0MB) used = 15424152 (14.709617614746094MB) free = 9741672 (9.290382385253906MB) 61.29007339477539% used From Space: capacity = 1572864 (1.5MB) used = 1013016 (0.9660873413085938MB) free = 559848 (0.5339126586914062MB) 64.40582275390625% used To Space: capacity = 1572864 (1.5MB) used = 0 (0.0MB) free = 1572864 (1.5MB) 0.0% used PS Old Generation capacity = 84934656 (81.0MB) used = 62824456 (59.91407012939453MB) free = 22110200 (21.08592987060547MB) 73.96798781406733% usedps命令ps -p 进程ID -o vsz,rss VSZ RSS 3701784 413924 VSZ是指已分配的线性空间大小,这个大小通常并不等于程序实际用到的内存大小,产生这个的可能性很多,比如内存映射,共享的动态库,或者向系统申请了更多的堆,都会扩展线性空间大小。 RSZ是Resident Set Size,常驻内存大小,即进程实际占用的物理内存大小pmap命令pmap -x 进程ID Address Kbytes RSS Dirty Mode Mapping 0000000000400000 4 4 0 r-x-- java 0000000000600000 4 4 4 rw--- java 00000000017f8000 2256 2136 2136 rw--- [ anon ] 00000000c4000000 82944 63488 63488 rw--- [ anon ] 00000000c9100000 572416 0 0 ----- [ anon ] 00000000ec000000 27648 27136 27136 rw--- [ anon ] 00000000edb00000 300032 0 0 ----- [ anon ] ...... total kB 3701784 413924 400716 Address: 内存分配地址 Kbytes: 实际分配的内存大小 RSS: 程序实际占用的内存大小 Mapping: 分配该内存的模块的名称 anon,这些表示这块内存是由mmap分配的JAVA应用内存分析JAVA进程内存 = JVM进程内存+heap内存+ 永久代内存+ 本地方法栈内存+线程栈内存 +堆外内存 +socket 缓冲区内存+元空间 linux内存和JAVA堆中的关系 RES = JAVA正在存活的内存对象大小 + 未回收的对象大小 + 其它 VIART= JAVA中申请的内存大小,即 -Xmx -Xms + 其它 其它 = 永久代内存+ 本地方法栈内存+线程栈内存 +堆外内存 +socket 缓冲区内存 +JVM进程内存JVM内存模型(1.7与1.8之间的区别)算一下求和可以得知前者总共给Java环境分配了128M的内存,而ps输出的VSZ和RSS分别是3615M和404M。 RSZ和实际堆内存占用差了276M,内存组成分别为: JVM本身需要的内存,包括其加载的第三方库以及这些库分配的内存 NIO的DirectBuffer是分配的native memory 内存映射文件,包括JVM加载的一些JAR和第三方库,以及程序内部用到的。上面 pmap 输出的内容里,有一些静态文件所占用的大小不在Java的heap里 JIT, JVM会将Class编译成native代码,这些内存也不会少,如果使用了Spring的AOP,CGLIB会生成更多的类,JIT的内存开销也会随之变大 JNI,一些JNI接口调用的native库也会分配一些内存,如果遇到JNI库的内存泄露,可以使用valgrind等内存泄露工具来检测 线程栈,每个线程都会有自己的栈空间,如果线程一多,这个的开销就很明显 当前jvm线程数统计:jstack 进程ID |grep ‘tid’|wc –l (linux 64位系统中jvm线程默认栈大小为1MB) ps huH p 进程ID|wc -l ps -Lf 进程ID | wc -l top -H -p 进程ID cat /proc/{pid}/status jmap/jstack 采样,频繁的采样也会增加内存占用,如果你有服务器健康监控,这个频率要控制一下jstat命令JVM的几个GC堆和GC的情况,可以用jstat来监控,例如监控某个进程每隔1000毫秒刷新一次,输出20次 jstat -gcutil 进程ID 1000 20 S0 S1 E O M CCS YGC YGCT FGC FGCT GCT 0.00 39.58 95.63 74.66 98.35 96.93 815 4.002 3 0.331 4.333 0.00 39.58 95.76 74.66 98.35 96.93 815 4.002 3 0.331 4.333 41.67 0.00 1.62 74.67 98.35 96.93 816 4.006 3 0.331 4.337 41.67 0.00 1.67 74.67 98.35 96.93 816 4.006 3 0.331 4.337 41.67 0.00 3.12 74.67 98.35 96.93 816 4.006 3 0.331 4.337 41.67 0.00 3.12 74.67 98.35 96.93 816 4.006 3 0.331 4.337 41.67 0.00 8.39 74.67 98.35 96.93 816 4.006 3 0.331 4.337 41.67 0.00 9.85 74.67 98.35 96.93 816 4.006 3 0.331 4.337 S0 年轻代中第一个survivor(幸存区)已使用的占当前容量百分比 S1 年轻代中第二个survivor(幸存区)已使用的占当前容量百分比 E 年轻代中Eden(伊甸园)已使用的占当前容量百分比 O old代已使用的占当前容量百分比 P perm代已使用的占当前容量百分比 YGC 从应用程序启动到采样时年轻代中gc次数 YGCT 从应用程序启动到采样时年轻代中gc所用时间(s) FGC 从应用程序启动到采样时old代(全gc)gc次数 FGCT 从应用程序启动到采样时old代(全gc)gc所用时间(s) GCT 从应用程序启动到采样时gc用的总时间(s)总结正常情况下jmap输出的内存占用远小于 RSZ,可以不用太担心,除非发生一些严重错误,比如PermGen空间满了导致OutOfMemoryError发生,或者RSZ太高导致引起系统公愤被OOM Killer给干掉,就得注意了,该加内存加内存,没钱买内存加交换空间,或者按上面列的组成部分逐一排除。这几个内存指标之间的关系是:VSZ >> RSZ >> Java程序实际使用的堆大小
-
K8S pod内存告警分析 背景:目前prometheus 给pod的内存告警阀值设置的80%,由于JVM 设置最高申请内存为pod limit 的75%,通过arthas查看到堆内存和元空间占用内存之和跟prometheus告警值不同。一、排查步骤:1、prometheus 告警使用参数**使用container_memory_rss值进行告警- alert: Pod内存使用率 expr: | sum(container_memory_rss{image!=""}) by(pod, namespace) / sum(container_spec_memory_limit_bytes{image!=""}) by(pod, namespace) * 100 != +inf > 80 for: 5m labels: severity: warning annotations: summary: "命名空间: {{ $labels.namespace }} | Pod名称: {{ $labels.pod }} 内存使用大于80% (当前值: {{ $value }})"2、找到pod运行node节点[root@pro-k8s-master ~]# kubectl -n msApp3、通过Docker state 查看容器资源[root@k8s-node1 ~]# docker ps |grep mayi-center-64ddfdd6-5crl6 [root@pro-node1 ~]# docker ps |grep mayi-center-64ddfdd6-2dzpt b6b3733024c2 192.168.0.45/middleground-business-center/pro_mayi-center "sh -c 'JAVA $JAVA_O…" 7 days ago Up 7 days k8s_mayi-center_mayi-center-9d5d588c5-d7sgd_msapp_eac4e708-bd0a-483c-b5d4-734f95c9f1c7_0 5770fe14e7aa registry.cn-shanghai.aliyuncs.com/google_containers/pause:3.1 "/pause" 7 days ago Up 7 days k8s_POD_mayi-center-9d5d588c5-d7sgd_msapp_eac4e708-bd0a-483c-b5d4-734f95c9f1c7_0 [root@k8s-node1 ~]#docker state b6b3733024c2 CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS b6b3733024c2 k8s_mayi-center_mayi-center-9d5d588c5-d7sgd_msapp_eac4e708-bd0a-483c-b5d4-734f95c9f1c7_0 4.31% 1.788GiB / 2GiB 89.40% 0B / 0B 1.52MB / 137MB 1324、通过top -p 查看容器内存情况[root@pro-k8s-node1 ~]# top -p 794890 PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 794890 root 20 0 7483084 1.8g 15448 S 6.7 2.9 392:48.42 java5、通过ps查看[root@pro-k8s-node1 ~]# ps -ef|grep mayi root 277280 257311 0 10:33 pts/0 00:00:00 grep --color=auto mayi root 794890 794871 3 Sep08 ? 06:32:39 java -XX:+UseContainerSupport .....mayi-center ..... -jar /app.jar [root@pro-k8s-node1 ~]# ps -e -o 'pid,comm,args,pcpu,rsz,vsz,stime,user,uid' | grep 794890 279183 grep grep --color=auto 794890 0.0 960 112712 10:35 root 0 794890 java java -XX:+UseContainerSuppo 3.8 1883224 7483084 Sep08 root 06、查看jvm内存通过arthas-boot 查看堆内存和非堆内存二、查看结果1、通过top查看到容器内对应java进程占用内存为1.7G,跟prometheus几乎一致2、通过ps 查看到容器内对应java进程占用内存为1.7G+,跟prometheus几乎一致3、通过docker state 查看到容器内存查看内存内存为1.7G+,跟prometheus几乎一致4、通过arthas-boot查看到jvm堆内存和非堆内存之和为1.6G+。三、结论由于通过prometheus pod内存告警和实际jvm查看到的内存不同带来的疑问,初步怀疑是jvm本身占用了部分内存。